Introduction
This article introduces Contentful ( a cloud hosted, headless, Content Management System (CMS)) and the graph database Neo4j. I have written a utility that allows data stored in Contentful to be imported into a Neo4j graph database. I’ll leave detailed explanations of what this can do until after I have explained the two systems. There are probably very few people who are familiar with both of these products so I will start with an introduction to each.
Contentful
Contentful is a cloud hosted headless CMS.
Contentful does provide a user-interface for the content editors:

This is how the editors enter the various fields that make up a content type.
However Contentful does not provide a user interface for the “application”. Instead it provides various api’s that allow the developer to use the data in the CMS however they like. This is very powerful in that you are not limited by the user interface provided by a traditional CMS – you get to use it however you like. Given that the data is served by a rest api (with GraphQL coming soon) then you are not restricted by language.
Data in contentful is partitioned into Spaces. This is the equivalent of a distinct database.
Spaces contain three kinds of things:
- Content Types – These are the schema of the content (it’s a list of fields, but fields may reference other content types or be lists of other content types )
- Entries – Instances of content types. For example the above picture shows a Category content entry.
- Assets – External images. Contentful acts a a document library and image resizing service for these.
Entries and Assets can be in preview or published states. There are two main api feeds preview and publish. Publish shows only published items, where as preview will also include more recent items that are in preview mode.
The contentful space that I am using for my examples is “The example project” which you get by default when you sign up to contentful. It is the content for a website that explains how to use Contentful from a number of programming languages.
Here are the content types within this space:

Creating a user interface for these is beyond the scope of this article but you can find plenty of examples.
Neo4j
Neo4j is a graph database.
Unlike traditional relational databases it works with nodes and relationships.
Nodes are the entities of the system and may have a label and attributes.
Nodes may be connected by relationships (which can be directional). Relationships can also have attributes.
You can query a neo4j database using a query language called Cypher.
Neo4j also has an api that allows other systems to connect to it – these can be used to query and modify the graph.

Here I have written one of the simplest queries possible in neo4j:
MATCH (a:category) RETURN a
This is find me all nodes of label category and return them. Here I have shown the details of one of the nodes in the browser.

This is a more complex query:
MATCH(a:category)-[]-(b) RETURN a, b
This reads find me all nodes that are categories that have any kind of relationship to another node and return these nodes.
Note the visual nature of the query language. Nodes are contained in normal brackets but are displayed as circles in the browser!
There is far more that can be done with Neo4j and Cypher but this is a good introduction.
How to go from Contentful to Neo4j
Now I have introduced the two platforms I will explain how to move data from Contentful to Neo4j.
There are some warnings I should give you before you start to use it.
- This will delete the neo4j database that it is pointed at before loading the data from the Contentful Space. Do not run this on a graph that you don’t have backed up.
- If the utility can’t migrate a field it will skip it and log it to the output. Let me know if this happens and I will try to correct the utility.
- I currently write the entire database in one transaction. This may not work well for very large contentful spaces.
I typically use Neo4j for analytical databases that get dropped and recreated frequently. This may vary from other peoples usage. This means that I don’t need to worry about database backups or migrations. I do need to worry about loading the database quickly.
My utility is available in the following github repo:
https://github.com/chriseyre2000/contentful-to-neo4j
The utility is written in javascript and uses node to run the command. There are detailed instructions in the readme. I chose Javascript for this as this seems to be the most commonly used language for Contentful.

Here is what you get when you ask for all data (note in a realistically sized contentful system neo4j would cap the displayed nodes a 100).
This shows the relationships between the various nodes in the system.
Here is the schema of the graph database:
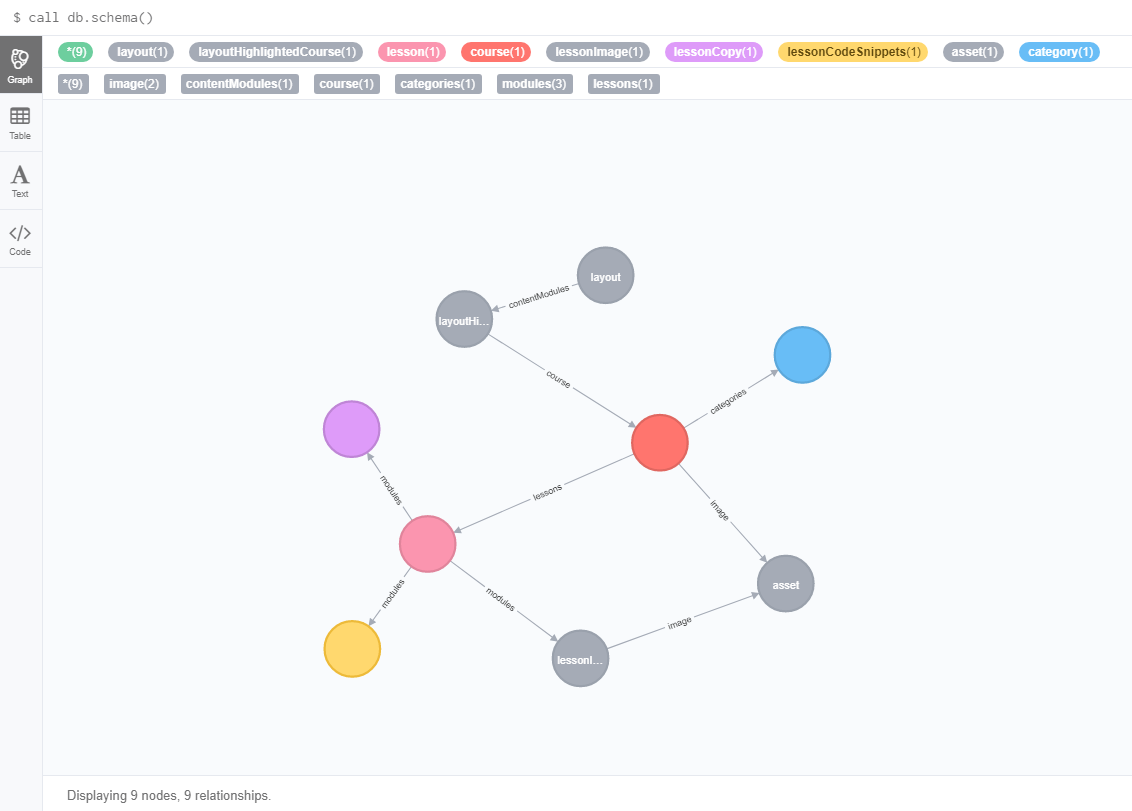
This shows the relationships between the various content types.
This is fun to play with and with more detailed queries can be informative.
However there are more powerful queries such as:

This returns the asset nodes that are not linked to by any entry. These are orphan images that may have been published by mistake. This is something that the contentful UI cannot do.
You can also view the data in text form:

Summary
Hopefully this has given you a useful insight into what Contentful and Neo4j can be used for. Feel free to use my utility (at your own risk). It does make managing a Contentful system considerably easier – given that you can freely query the data.

