This Pr has now been merged!
There is even a release candidate PR
So we are looking at 11.14.0
Wardley Maps are getting closer to being included in MermaidJS
This PR is getting close to being merged into MermaidJs.
This will be a great boost to the Wardley Map tools so that we will have “native” Wardley Map support in github and notion (at least).
Congrats to tractorjuice for doing the hard work.
AI and Managing Outsourcing
There are claims that AI has solved writing code. This implies that we have recreated the outsourcing model.
The problem is that writing code is not the goal. We really want to solve problems and find using a computer to do the job is the most efficient way to do this. A large part of the value I bring is to understand how a system works. That way we can make changes that improve the existing system.
Some years ago a project was run at a company where I worked. The manager thought it was clever to hire a team of the cheapest developers he could find. The team was limited to 7 people since that was the power supply limit of the available room. The two permanent developers did their best to give instructions to this team. We had a suite of acceptance tests that was heading to being green as the critical launch day arrived. Two of the team had commit rights revoked due to repeatedly committing broken code.
Not being involved in the project I left the office at my usual end of day time. The next morning I arrived and found out about the chaos that had ensued.
2 of the 7 subsystems deployed to production were simply mocks. These were sufficient to get the test scripts to work.
The team QA had quit twice (the first time being talked down). The two in house devs had to implement minimal versions of the services. Mangement had introduced a no-one goes home til this works policy after I had left. The devs had been checked into a nearby hotel late that night!
In the end we had a shop that could not sell anything until halfway through the next day.
It took about a year to get the system into a sane state before we replaced it again.
Management had considered this a success. This was mostly due to us eliminating an Oracle DB that would have cost a fortune to renew.
This is what happens with a small team of developers. This is exactly what people are doing with AI. They are generating systems from incomplete specifications.
Why is my screenshare going slow?
I had fun this week with using google meet to share my desktop it became so slow that I could not communicate effectively. There seem to be two causes:
Google meet is less effective on Firefox than on Chrome. This could be by design. Moving from Firefox to Chrome for the sharing made a big improvement, but did not fix everything.
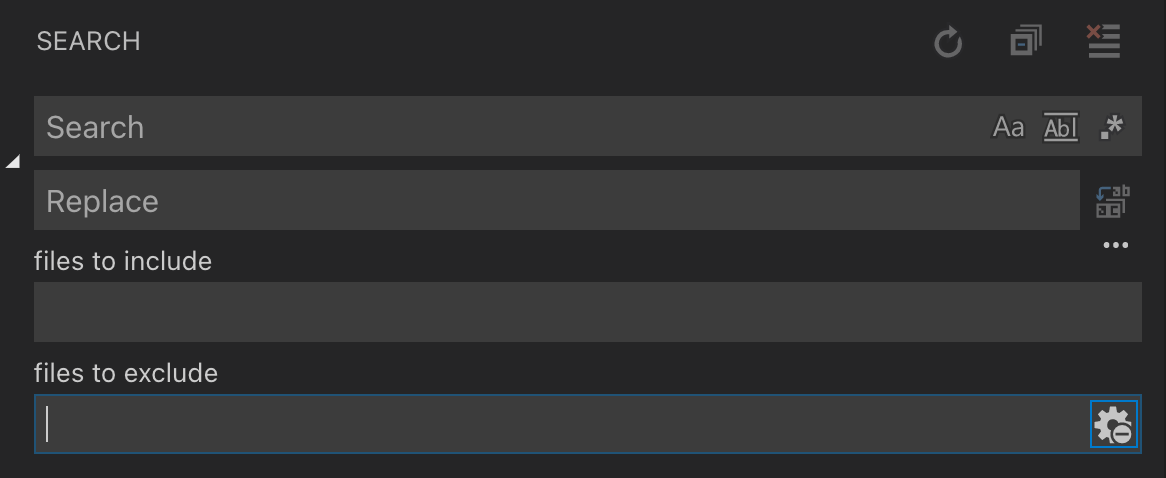
The second issue was found using top. I had a number of instances of rg that started to use 100% of the CPU. This coincident with VS Code starting searches that it did not finish.
In the end it came down to the small gear icon shown below. It needs to be in the “Use exclude settings and ignore file mode”
Flow and Work In Progress
Near the beginning of my career the lag between writing code and it being deployed in production was about 6 months. It could be 2 weeks before a tester deployed it to check it. Feedback was almost non-existant and you frequently had to investigate what you had written all that time ago (plus all the other changes the team had made to it).
We had what would be described now as long lived branches. One of my colleagues had to maintain fixes for bugs and feature parity across 7 active branches.
Today it is possible to have a small change be suggested in the morning, and implement it, then deploy it that afternoon. This is a 180:1 improvement in throughput!
Releasing every six months resulted in frantic planning and regression testing. This encouraged huge batches of work, with regression test cycles and lots of handovers.
Now we try and release as little in a batch as we can. If there is any risk it can be a single PR deploy. If bugs are found you can quickly isolate the cause and fix/revert.
There is now realistic feedback on changes.
We now try and strip every PR down to something that adds value to a system. It may take 3 of these before a customer sees a change, but the risk of merge conflicts has almost been eliminated.
The practical benefit is that you can experiment with small improvements and find out how to improve the system as a whole.
We also release far more features than in the 6 month cycles we used to have.
e2e tests vs contract tests
In order to discuss this I need to define my terms as e2e tests have many meanings. Here I base them upon outside in tests of the system that you support, tested mostly. through the user interface or public api.
For contract tests I mean systems like Pact which ensure that for a given set of api calls a certain response is given.
The system that I mainly work on has a react UI served by graphql endpoints. The e2e tests use Playwright to automate the UI and perform checks. The frontend code calls the real backend code. I have had to mock out some of the external dependencies (we can’t have an e2e test making credit card payments).
The frontend code has unit tests. The backend code has unit tests. The e2e tests ensures that one can talk to the other in a useful manner.
Contract tests can prove that a given contract will still return what is expected where as an e2e test can also check. that the call is actually being made.
e2e tests do have downsides.:
- Slow
- Unstable
- Non specific errors
The main part of the slow is the setting up of the environment to run the tests. Only test enough to prove that the services are connected. Never loop through all inputs in an e2e test as this will be slow and will enhance any statistical failures.
Unstable is that these will break if the UI flow changes. They can also break if any of the external mocks change.
There are many ways for a test to fail so you don’t always get the cause shown.
The only way to overcome all of these is to have a way to run the same setup locally.
e2e tests also force you to understand all of the dependencies that you are using. Keep the boundaries as tight as you can. Sometimes this can be painful if you are consuming details from many services.
Web clients are fundamentally insecure
You can’t trust that a web client has not been compromised.
The only safe bet is to assume that any API that you expose to your web client is being directly used as an API.
The client side javascript code for a site makes great documentation for attacking your server.
A simple `wget -r URL will give you the html, css and javascript of most of the site.
The internal urls are stored in the javascript along with any of the graphql queries that you are using.
Developer tools in the browser plus a simple graphql client tool can give you access to far more than you expect.
HMRC Online Tax Return a review
This is an annual ritual in the Uk if you have been asked to fill one in.
The deadline is end of January but it actually covers the year to the previous April.
You are asked to enter data from various forms you have been sent over the year.
It fails to carry forward simple information from the previous year.
My name has not changed nor has my married status.
My employers name is longer than the maximum length that can be input!
The form is multipart asking you in early steps to determine how much of it you actually need to complete.
It is lacking a “hang on I need to ask someone for one field” option. This means you have to pause the process if you find you are missing a P11D.
Given that there are multiple steps I would like to be able to fill in the capital gains section even if I can’t complete the employee section.
The joke is that they already have all this information. The only important part is making you state that you believe this to be correct.
I don’t want to do all this in the new app that they created for it.
Beyond Equality: Compare
There are lots of ways to check for equality. Funx even defines a protocol for it.
This is useful in a number of situations and combines well with other protocols.
There are many situations in which you don’t merely want to say that two things are different you need to know what is different. For this I typically use a compare function that either returns :ok or a list of Validation errors.
Having a simple contract like this makes them easily composable into rulesets. Rulesets can know when it is appropriate to apply a given compare. Using this approach allows a system to provide actionable feedback. Its more than a computer says no, its a these are the problems that I have found.
This is similar to the changeset that Ecto provides for databases but at the domain model level.
Extracting composable compares and rulesets makes the domain logic explicit and testable. This will make extensions easier.
Warp as a terminal
I have been using https://www.warp.dev/ as a terminal for a while.
The ai hints are sometimes useful, but it really shines as a multi-tab terminal.
Recently I accedentally found it has a built in IDE. This will be something that will be worth looking at once they actually have an auto-save feature. Once you have been using auto-save for a while you lose the almost continuous ctrl-s twitch.
